In honor of the upcoming PyCon (which I’ll be attending on behalf of The Open Planning Project) I decided to write about Python today.
Some time back I wrote myself a simple utility for synchronizing Safari downloads (the book service, not the web browser), and I decided to polish it up, release it, and write about the process. This is the first of two parts where I will talk about my first time handling the start to finish of publishing an open source python package. The next part will be a tutorial on how to screen scrape the web, from inspecting the HTTP headers to using CSS selectors with lxml to parse out the interesting data.
Anyway, back to the topic at hand. If you’ve never heard of Safari, and you’re a tech professional, than I hope it’s because you have personal access to the Library of Alexandria. If not, then let me be your personal cluestick. For about the price of five tech books (per year), you can maintain an online bookshelf that gives you access of up to 120 books in that year. In practice, I think I average about 30, but this also gives you the ability to search through their entire library to find the answers you need. When you find a book, you add can add it to your bookshelf with two clicks (Thanks Amazon!) and then start reading. What’s more, the service includes 5 downloads per month (usually one chapter or section of a book), that give you a personalized PDF for offline reading.
My only problem with the service is managing the downloads. Once you’ve downloaded a chapter, it will always be available to you (at least as long as you have an account), but the PDFs are auto-generated on demand, and when you save them, you end up with files named something like 0EITGkillY6ALIkill3kHfWkillC4RwjkillwKb69kill736MGkillY4UuykillEJTsC.pdf. I tried to give them sensible names, and organize them, but it was always a pain, and I always had the weirdest urges just afterward. To top it all off, the last time I changed computers, I decided not to copy the files (knowing that I could re-download them), so I was left with a lot of manual work to do.
Well, I’ve been telling myself for some time that I wanted to play with lxml (it’s the fast python library for working with XML and HTML). Also, I’ve been working entirely in javascript lately, so I felt that it was time to stretch some mental muscles and get something done in python. For the impatient, you can get a copy of the script by typing the following at a terminal:
1 2 | |
If the output you get looks something like this: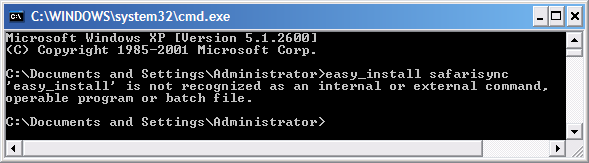
Fear not, poor windows user, I intend to release a simple executable to coincide with the second part of this article. If you don’t feel like waiting, you can download and install python, then download and install setuptools, and finally fix up your PATH environment variable.
For everyone else, you can start playing along. Just type safarisync to start the process, or safarisync --help to get a list of options.
Since I’ve only worked with lxml peripherally before (as it was embedded into other projects I was working on), I ended up writing three completely different versions. The first version was fully functional, using the cookie handling that I learned from this well written tutorial. It also iterated through all of the elements in the tree to find the ones we were interested in. Just after finishing it up, I stumbled across this quick intro to lxml, written by a colleague of mine (Ian Bicking). If you haven’t heard him speak somewhere already, than chances are high that either you’ve used something he’s written, or used something based on something he’s written.
His article introduced me to the CSS selector engine and form handling now built into lxml. Thus was born the second version of safarisync. The only problem was that it usually didn’t work. In the debug shell, I could usually get the code to run, after some tinkering, but never standalone.
The first problem I always had was unnecessarily hard to diagnose. I was consistently receiving a UnicodeDecodeError from lxml. I was confused by this because the string I passed in had the proper encoding specified within:
1
| |
I received the help I needed from my colleague Luke Tucker (of Melkjug fame, which by the way, you should check out, they just released a new version). As it turns out, there was a problem in the error handling of lxml such that if you had a bug AND you had unicode data, instead of getting the correct bug reported, you got a UnicodeDecodeError. He suggested I strip any unicode data and try the same operations to get to the real error. Thankfully, I’ve been told that this is fixed in the latest version.
Solving the last problem took me outside of the debugging shell, and into the bowels of lxml. It’s partially written in Cython, which is a python-like language that compiles down to C. This means (in theory) that you get the speed of C with the beauty of Python. In practice, this is only half true. You get the speed of C. Beauty, however, is in the eye of the beholder. In any case, peering through the code showed me that while the new form handling code uses python for network access, the rest of lxml uses the built-in downloading facilities of libxml, the C library it wraps. This means that you have to avoid lxml’s network helpers almost entirely if you need to handle cookies.
The third version of the code can be found at my public source repository. The interesting code is found in safarisync.py. I’ve tried to comment it well enough that you can follow through, even without my help. I’ve had it reviewed by Ian and Robert Marianski, another colleague of mine and talented python programmer. He helped me with the details necessary to publish the package on PyPI. (For example, if you want your package to have an executable shortcut, you need to create a specially named entry point in setup.py).
Well, thanks for tuning in. Come back next week for a detailed tutorial teaching you how to write your own screen scraping tools.